

RCNN系列阅读笔记
RCNN
全称为Region with CNN feature,可以说是利用深度学习进行目标检测的开山之作
其中RCNN可以分为四个步骤:
- 一张图像生成1K~2K个 候选区域(使用Selective Search方法)
- 对每个候选区域,使用深度网络 提取特征
- 特征送入每一类的 SVM 分类器,判别是否属于该类
- 使用回归器 精细修正候选框位置
Selective Search方法
一张图像中可能存在多个物体需要分别定位和分类。显然,在训练分类器之前,需要使用一些方法将图像划分为小的区域,这些方法统称为Region Proposal,而Selective Search就是其中一种方法,而该算法主要分为两个内容:Hierarchical Grouping Algorithm、Diversification Strategies
ⅠHierarchical Grouping Algorithm
图像中区域特征比像素更具代表性,首先使用Felzenszwalb and Huttenlocher的方法产生图像初始区域,使用贪心算法对区域进行迭代分组。
算法的步骤如下:
- 计算所有邻近区域之间的相似性;
- 两个最相似的区域被组合在一起;
- 计算合并区域和相邻区域的相似度;
- 重复2、3过程,直到整个图像变为一个地区。
Ⅱ Diversification Strategies
这个方法就是计算相似度的,主要从四个方面进行展开考虑,包括颜色相似度、纹理相似度、尺度相似度、填充相似度,然后用一个复杂的公式计算。没啥意义,不罗列了
深度网络提取特征
首先将2k个候选区域缩放成227*227的pixel,然后将候选区域输入事先训练好的AlexNet CNN网络获取4096维的特征得到2000×4096维矩阵(每行一个候选区域)
特征送入每一类的 SVM 分类器
将2000×4096维特征与20个SVM组成的权值矩阵4096×20相乘,获得2000×20维矩阵表示每个建议框是某个目标类别的得分。分别对上述2000×20维矩阵中每一列即每一类进行 非极大值抑制剔除重叠建议框,得到该列即该类中得分最高的一些建议框。
非极大值抑制:
非极大值抑制,简称为NMS算法,英文为Non-Maximum Suppression。其思想是搜素局部最大值,抑制非极大值。目标检测的过程中在同一目标的位置上会产生大量的候选框,这些候选框相互之间可能会有重叠,此时我们需要利用非极大值抑制找到最佳的目标边界框,消除冗余的边界框。
前提:目标边界框列表及其对应的置信度得分列表,设定阈值,阈值用来删除重叠较大的边界框。
IoU:intersection-over-union,即两个边界框的交集部分除以它们的并集。
流程如下:
- 根据置信度得分进行排序
- 选择置信度最高的比边界框添加到最终输出列表中,将其从边界框列表中删除
- 计算所有边界框的面积
- 计算置信度最高的边界框与其它候选框的IoU
- 删除IoU大于阈值的边界框
- 重复上述过程,直至边界框列表为空
使用回归器 精细修正候选框位置
对NMS处理后剩余的建议框进一步筛选。接着分别用20个回归器对上述20个类别中剩余的建议框进行回归操作,最终得到每个类别的修正后的得分最高的bounding box。
缺点
- 测试速度慢
- 训练所需空间大
fast-RCNN
网络结构
可以分为三个步骤:
- 一张图像生成1K~2K个 候选区域(使用Selective Search方法)
- 将图像输入网络得到相应的 特征图,将SS算法生成的候选框投影到特征图上获得相应的 特征矩阵
- 将每个特征矩阵通过ROI pooling层缩放到 7x7 大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果
结构如下:
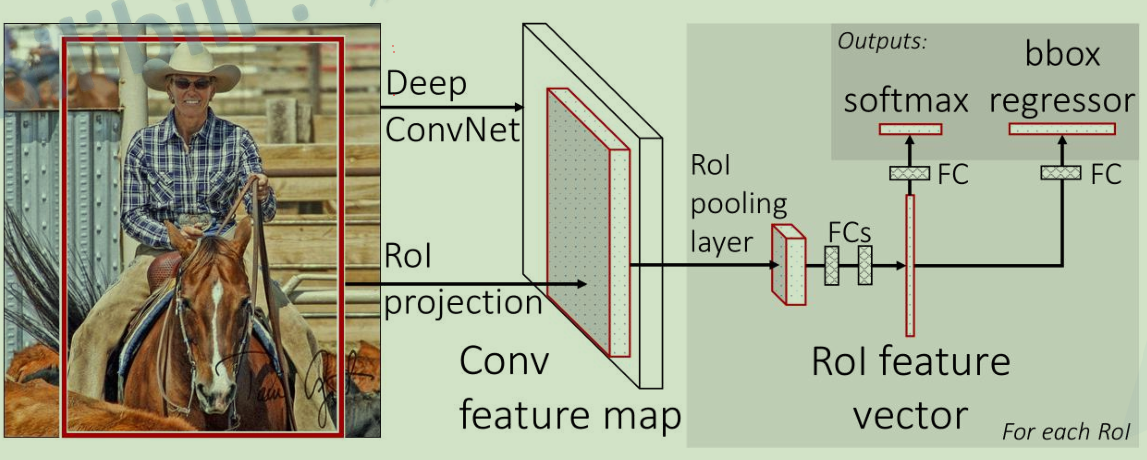
相比于RCNN,Fast-RCNN将整张图像送入网络,紧接着从特征图像上提取相应的候选区域,这些候选区域的特征 不需要再重复计算
在微调过程中,采用小批量采样,每个SGD小批量由N = 2个图像构成,这些图像是均匀随机选择的。使用大小为R = 128的小批量,从每个图像中采样64个RoIs。
RoI pooling是一个广泛应用在目标检测任务的卷积神经网络中的操作。它的目的是对不规范的输入进行max pooling,以获得固定尺寸的feature maps(例如7×7)。
分类器和边界框回归器
分类器(也就是上图的softmax对应的分类器)输出N+1个类别的概率(N为检测目标的种类, 1为背景)共N+1个节点
边界框回归器输出对应N+1个类别的候选边界框回归参数($d_x,d_y,d_w,d_h$),共$(N+1)\times4$个节点
然后可以计算:
$$
\begin{aligned}
&\hat{G}x=P_wd_x(P)+P_x \
&\hat{G}_y=P_hd_y(P)+P_y \
&\hat{G}_{w}=P{w}\exp(d_{w}(P)) \
&\begin{aligned}\hat{G}_h=P_h\exp(d_h(P))\end{aligned}
\end{aligned}
$$
其中,$P_x,P_y,P_w,P_h$分别为候选框的中心x,y坐标,以及宽高
$\hat{G}_x,\hat{G}_y,\hat{G}_w,\hat{G}_h$分别为最终预测的边界框中心x,y坐标,以及宽高
损失函数
Multi-task loss:
$L(p,u,t^u,v)=L_{cls}(p,u)+\lambda[u\geq1]L_{loc}(t^u,v)$
$p$是分类器预测的softmax概率分布$p=(p_0,p_1,···,p_k)$,$u$对应目标真实类别标签
①分类损失$L_{cls}\left(p,u\right)=-\log p_{u}$
②边界框回归损失$\lambda[u\geq1]L_{loc}(t^u,v)$中的$[u\geq1]$是艾弗森括号
$t^u$对应边界框回归器预测的对应类别$u$的回归参数$\left(t_x^u,t_y^u,t_w^u,t_h^u\right)$
$v$对应真实目标的边界框回归参数$\left(\nu_{x},\nu_{y},\nu_{w},\nu_{h}\right)$
$L_{loc}(t^u,\nu)=\sum_{i\in{x,y,w,h}}smooth_{L_1}(t_i^u-\nu_i)$
其中$$smooth_{L_1}(x)=\begin{cases}0.5x^2&\quad\text{if}|x|<1\|x|-0.5&\quad\text{otherwise}\end{cases}$$
Faster-RCNN
网络结构
Faster-RCNN可以理解为$RPN+Fast R-CNN$
可以分为三个步骤:
- 将图像输入网络得到相应的特征图
- 使用RPN结构生成候选框,将RPN生成的候选框投影到特征图上获得相应的特征矩阵
- 将每个特征矩阵通过ROI pooling层缩放到7x7大小的特征图,接着将特征图展平通过一系列全连接层得到预测结果
网络结构图如下所示:
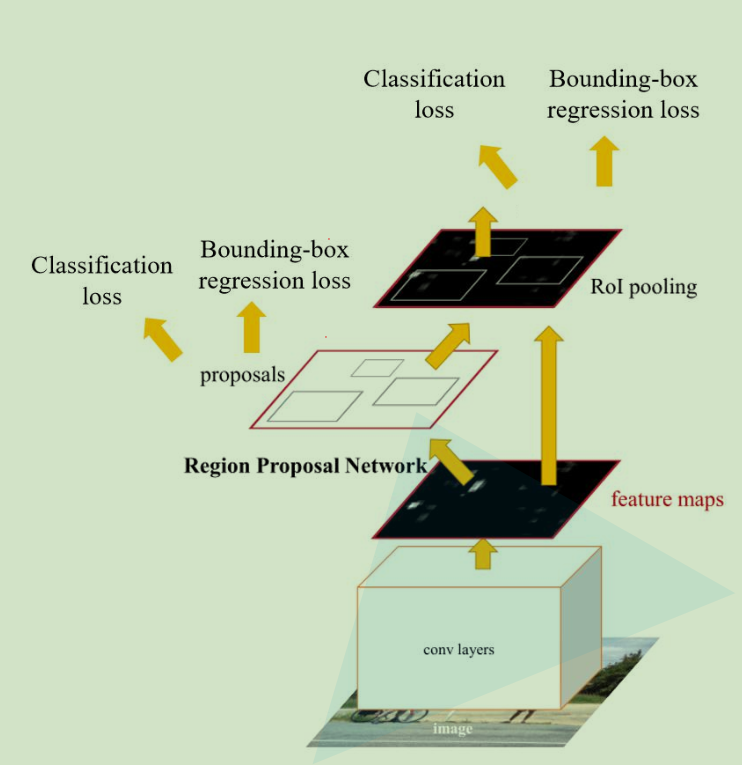
RPN
对于特征图上的每个3x3的滑动窗口,计算出滑动窗口中心点对应原始图像上的中心点,并计算出k个anchor boxes
如果使用的是VGG16 net,则滑动窗口维度(channel)为512,如果使用的是ZF Net,则滑动窗口维度为256
这$k$个anchor,对于cls layer需要输出2k个score;对于reg layer,需要输出4k个score
1、这$k$个anchor box如何产生?
使用$128\times128$,$256\times256$,$512\times512$三个规模的box area,并且有3个长宽比,分别为1:1、1:2和2:1,每个位置在原图上都对应有$3\times3$个anchor
2、训练数据如何采样?
采用了“以图像为中心”的采样策略来训练这个网络,每个小批量数据都来自于包含许多正负样本锚框的单个图像。虽然可以优化所有锚框的损失函数,但这会对负样本产生偏向,因为它们数量占主导地位。相反,我们在一个图像中随机采样256个锚框来计算一个小批量的损失函数,其中采样的正负样本锚框的比例最多为1:1。如果一个图像中的正样本少于128个,我们会用负样本填充小批量数据。
RPN-Multi-task loss
$L\left( \left{ p_i \right} ,\left{ t_i \right} \right) =\frac{1}{N_{cls}}\sum_i^{}{L_{cls}\left( p_i,p_{i}^{} \right)}+\lambda \frac{1}{N_{reg}}\sum_i^{}{p_{i}^{}L_{reg}\left( t_i,t_{i}^{*} \right)}$
其中,前半部分为分类损失,后半部分为边界框回归损失。
①参数解释:
$p_i$表示第$i$个anchor预测为真实标签的概率
$p_{i}^{*}$当为正样本时为1,为负样本时为0。
$t_i$表示预测第$i$个anchor的边界框回归参数
$t_{i}^{*}$表示第$i$个anchor对应的GTBOX的边界框回归参数
$N_{cls}$表示一个mini-batch里面的所有样本数量为256
$N_{reg}$表示anchor位置的个数(不是anchor个数)约2400
②公式解释:
$L_{cls}=-log(p_i)$,其实就是cross entropy
$L_{reg}\left( t_i,t_{i}^{} \right) =\sum_i^{}{smooth_{L_1}\left( t_i-t_{i}^{} \right)}$
其中$t_i=\left[ t_x,t_y,t_w,t_h \right] ,t_{i}^{}=\left[ t_{x}^{},t_{y}^{},t_{w}^{},t_{h}^{*} \right]$
Faster R-CNN
直接采用RPN Loss+ Fast R-CNN Loss的联合训练方法,这个好像tensorflow已经实现了,所以这里就不再赘述